Editor’s note: This post is part of Think SMART, a series focused on how leading AI service providers, developers and enterprises can boost their inference performance and return on investment with the latest advancements from NVIDIA’s full-stack inference platform.
NVIDIA Blackwell delivers the highest performance and efficiency, and lowest total cost of ownership across every tested model and use case in the recent independent SemiAnalysis InferenceMAX v1 benchmark.
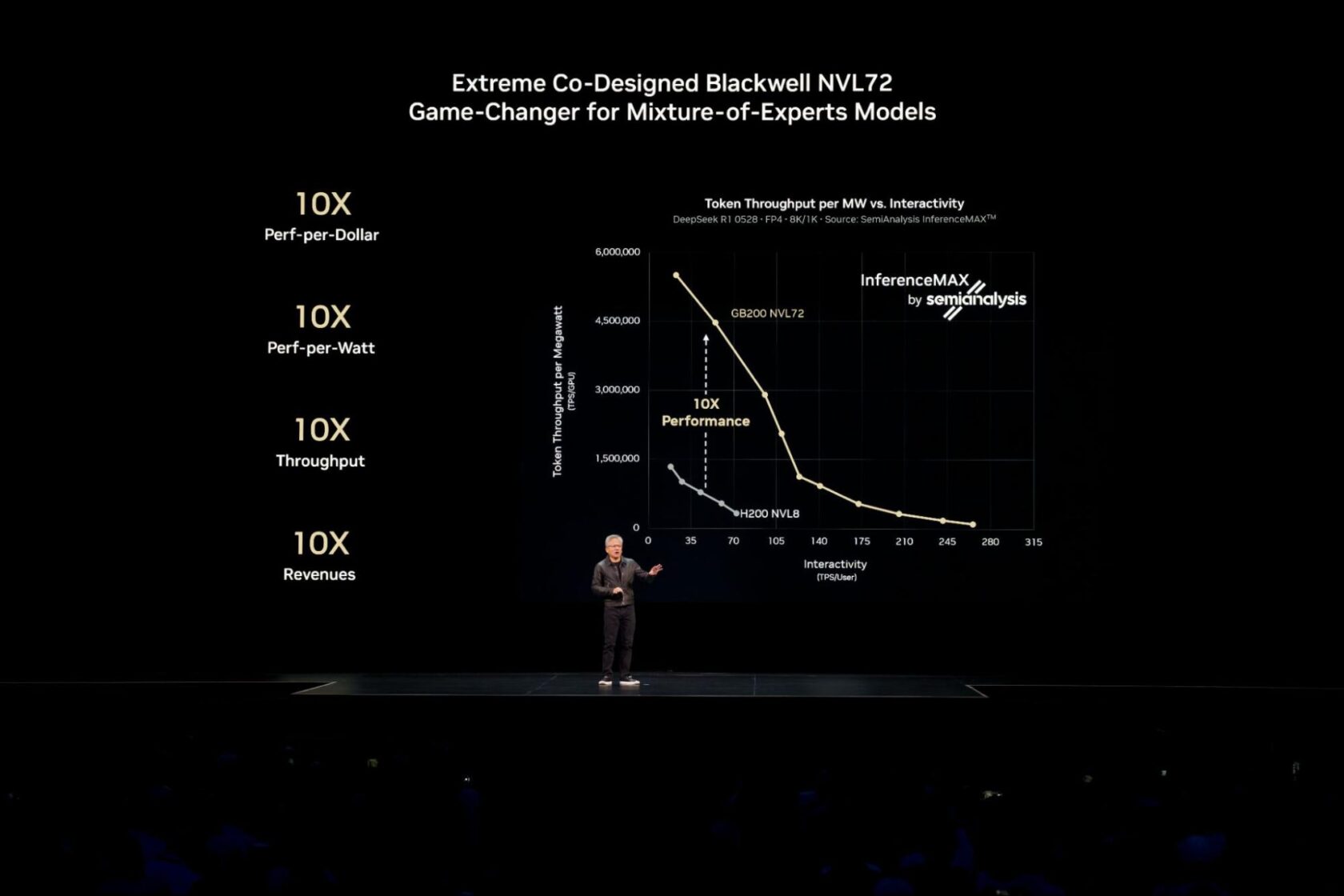
Achieving this industry-leading performance for today’s most complex AI models, such as large-scale mixture-of-experts (MoE) models, requires distributing (or disaggregating) inference across multiple servers (nodes) to serve millions of concurrent users and deliver faster responses.
The NVIDIA Dynamo software platform unlocks these powerful multi-node capabilities for production, enabling enterprises to achieve this same benchmark-winning performance and efficiency across their existing cloud environments. Read on to learn how the shift to multi-node inference is driving performance, as well as how cloud platforms are putting this technology to work.
For AI models that fit on a single GPU or server, developers often run many identical replicas of the model in parallel across multiple nodes to deliver high throughput. In a recent paper, Russ Fellows, principal analyst at Signal65, showed that this approach achieved an industry-first record aggregate throughput of 1.1 million tokens per second with 72 NVIDIA Blackwell Ultra GPUs.
When scaling AI models to serve many concurrent users in real time, or when managing demanding workloads with long input sequences, using a technique called disaggregated serving unlocks further performance and efficiency gains.
Serving AI models involves two phases: processing the input prompt (prefill) and generating the output (decode). Traditionally, both phases run on the same GPUs, which can create inefficiencies and resource bottlenecks.
Disaggregated serving solves this by intelligently distributing these tasks to independently optimized GPUs. This approach ensures that each part of the workload runs with the optimization techniques best suited for it, maximizing overall performance. For today’s large AI reasoning and MoE models, such as DeepSeek-R1, disaggregated serving is essential.
NVIDIA Dynamo easily brings features like disaggregated serving to production scale across GPU clusters.
It’s already delivering value.
Baseten, for example, used NVIDIA Dynamo to speed up inference serving for long-context code generation by 2x and increase throughput by 1.6x, all without incremental hardware costs. Such software-driven performance boosts enable AI providers to significantly reduce the costs to manufacture intelligence.
Much like it did for large-scale AI training, Kubernetes — the industry standard for containerized application management — is well-positioned to scale disaggregated serving across dozens or even hundreds of nodes for enterprise-scale AI deployments.
With NVIDIA Dynamo now integrated into managed Kubernetes services from all major cloud providers, customers can scale multi-node inference across NVIDIA Blackwell systems, including GB200 and GB300 NVL72, with the performance, flexibility and reliability that enterprise AI deployments demand.
The push towards enabling large-scale, multi-node inference extends beyond hyperscalers.
Nebius, for example, is designing its cloud to serve inference workloads at scale, built on NVIDIA accelerated computing infrastructure and working with NVIDIA Dynamo as an ecosystem partner.
Disaggregated AI inference requires coordinating a team of specialized components — prefill, decode, routing and more — each with different needs. The challenge for Kubernetes is no longer about running more parallel copies of a model, but rather about masterfully conducting these distinct components as one cohesive, high-performance system.
NVIDIA Grove, an application programming interface now available within NVIDIA Dynamo, allows users to provide a single, high-level specification that describes their entire inference system.
For example, in that single specification, a user could simply declare their requirements: “I need three GPU nodes for prefill and six GPU nodes for decode, and I require all nodes for a single model replica to be placed on the same high-speed interconnect for the quickest possible response.”
From that specification, Grove automatically handles all the intricate coordination: scaling related components together while maintaining correct ratios and dependencies, starting them in the right order and placing them strategically across the cluster for fast, efficient communication. Learn more about how to get started with NVIDIA Grove in this technical deep dive.
As AI inference becomes increasingly distributed, the combination of Kubernetes and NVIDIA Dynamo with NVIDIA Grove simplifies how developers build and scale intelligent applications.
Try NVIDIA’s AI-at-scale simulation to see how hardware and deployment choices affect performance, efficiency and user experience. To dive deeper on disaggregated serving and learn how Dynamo and NVIDIA GB200 NVL72 systems work together to boost inference performance, read this technical blog.
For monthly updates, sign up for the NVIDIA Think SMART newsletter.