Data-hungry workloads such as machine learning and data analytics have become commonplace. To cope with these compute-intensive tasks, enterprises need accelerated servers that are optimized for high performance.
Intel’s 3rd Gen Intel Xeon Scalable processors (code-named “Ice Lake”), launched today, are based on a new architecture that enables a major leap in performance and scalability. These new systems are an ideal platform for enterprise accelerated computing, when enhanced with NVIDIA GPUs and networking, and include features that are well-suited for GPU-accelerated applications.
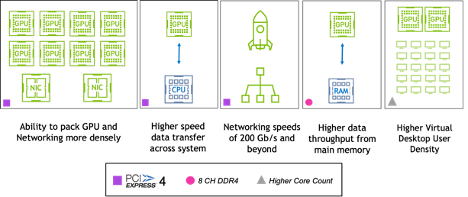
The move to PCIe Gen 4 doubles the data transfer rate from the prior generation, and now matches the native speed of NVIDIA Ampere architecture-based GPUs, such as the NVIDIA A100 Tensor Core GPU. This speeds throughput to and from the GPU, which is especially important to machine learning workloads that involve vast amounts of training data. This also improves transfer speeds for data-intensive tasks like 3D design for NVIDIA RTX Virtual Workstations accelerated by the powerful NVIDIA A40 data center GPU and others.
Faster PCIe performance also accelerates GPU direct memory access transfers. Faster I/O communication of video data between the GPU and GPUDirect for Video-enabled devices delivers a powerful solution for live broadcasts.
The higher data rate additionally enables networking speeds of 200Gb/s, such as in the NVIDIA ConnectX family of HDR 200Gb/s InfiniBand adapters and 200Gb/s Ethernet NICs, as well as the upcoming NDR 400Gb/s InfiniBand adapter technology.
The Ice Lake platform supports 64 PCIe lanes, so more hardware accelerators – including GPUs and networking cards – can be installed in the same server, enabling a greater density of acceleration per host. This also means that greater user density can be achieved for multimedia-rich VDI environments accelerated by the latest NVIDIA GPUs and NVIDIA Virtual PC software.
These enhancements allow for unprecedented scaling of GPU acceleration. Enterprises can tackle the biggest jobs by using more GPUs within a host, as well as more effectively connecting GPUs across multiple hosts.
Intel has also made Ice Lake’s memory subsystem more performant. The number of DDR4 memory channels has increased from six to eight and the data transfer rate for memory now has a maximum speed at 3,200 MHz. This allows for greater bandwidth of data transfer from main memory to the GPU and networking, which can increase throughput for data-intensive workloads.
Finally, the processor itself has improved in ways that will benefit accelerated computing workloads. The 10-15 percent increase in instructions per clock can lead to an overall performance improvement of up to 40 percent for the CPU portion of accelerated workloads. There are also more cores — up to 40 in the 8xxx variant. This will enable a greater density of virtual desktop sessions per host, so that GPU investments in a server can go further.
We’re excited to see partners already announcing new Ice Lake systems accelerated by NVIDIA GPUs, including Dell Technologies with the Dell EMC PowerEdge R750xa, purpose built for GPU acceleration, and new Lenovo ThinkSystem Servers, built on 3rd Gen Intel Xeon Scalable processors and PCIe Gen4, with several models powered by NVIDIA GPUs.
Intel’s new Ice Lake platform, with accelerator hardware, is a great choice for enterprise customers who plan to update their data center. Its new architectural enhancements enable enterprises to run accelerated applications with better performance and at data center scale and our mutual customers will be able to quickly experience its benefits.
Visit the NVIDIA Qualified Server Catalog to see a list of GPU-accelerated server models with Ice Lake CPUs, and be sure to check back as more systems are added.
The post NVIDIA-Powered Systems Ready to Bask in Ice Lake appeared first on The Official NVIDIA Blog.